After some careful analysis of which data structure to use for this project, I chose to implement my scheduler using a binary heap stored as an array [CLRS Chapter 6]. While the actual data structure itself is identical to the binary heap data structure discussed in CLRS, I did change the operations slightly to increase the overall efficiency of the heap to be used as a real priority queue.
The first change is in the Extract-Max function - rather than extracting the maximum node from the heap, then fixing the remaining nodes to maintain the heap property, I extract the maximum node and simply mark the heap as invalid. Any heap operations that are invoked on a "valid" heap proceed as they would normally. However, if the Insert operation is invoked on an "invalid" heap, then the new node is inserted at the newly vacated top position on the heap and moved down the heap to a legal position using a call to Heapify. For all commands besides Insert called on an "invalid" heap, the heap must first be "fixed" using the same procedure that Extract-Max would typically use, then the algorithms proceed as usual. The large gain here is obviously found only when an Insert call follows an Extract-Max call. Under the normal implementation, a call to Extract-Max would return the top element in the heap, swap the bottom element in the heap to the top position, and then call Heapify from the top position - an O(lg n) operation. If a call to Insert came next, the element would be added at the bottom of the heap and moved up to a legal position using Increase-Key - another O(lg n) operation. Clearly, in my implementation, we eliminate the need for one of these two O(lg n) operations in the situation in which Insert follows Extract-Max. This algorithmic improvement is key in the UNIX scheduler, since quite often a node is extracted and then re-inserted.
The second change is also in the Extract-Max function, and is really
a byproduct of the first change. Rather than dynamically allocating
memory and making a copy of the node during Extract-Max, I can simply pass
a pointer to the first node in the "invalid" heap with the stipulation
that if the client wants to keep the node, it must make its own copy before
calling any other function on the priority queue. Since the scheduler
only needs to look at the values in the maximum node, it is never necessary
to make this copy, and we gain the time that would have been required for
allocating the memory, copying the node, and freeing the memory using this
method.
Interface Methods
Per-Operation Basis
Since any of the operations could be called on an "invalid" heap, a
call to either Heapify or Increase-Key could be required
for any of the 5 basic operations - either directly in the case of Insert,
or indirectly via a call to Fix-Heap in the other 4 operations.
Since the asymptotic running times for both Heapify and Increase-Key
are bounded from above by O(lg n) where n is the number of nodes
in the queue [CLRS], all operations must have per-operation running times
of at least O(lg n). It makes more sense then, to use an amortized
analysis here, since the Fix-Heap operation is only necessary immediately
after a call to Extract-Max.
Amortized Analysis
The important insight to make here is that when Extract-Max is
called, it must pay an extra O(lg n) to account for the fact that
it leaves the heap in an "invalid" state, and it will need that O(lg
n) to return the heap to a "valid" state. Thus whenever any of the
other operations are called, we can ignore the cost of fixing the heap
since it was paid in advance by Extract-Max.
The best case input would be any sequence of operations in which each of the operations were only called under the following conditions:
The worst case input for each operation would involve the operations being called under the following conditions:
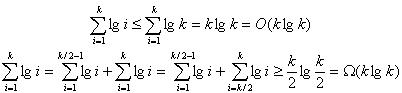
In choosing the best data structure to use from the list we were given, I made the following table to aid in my decision, where I include my solution for comparison.
Comparison of Candidate Data Structures
| Insert(K,I) | Delete(E) | Increase-Key(E,K) | Maximum() | Extract-Max() | Other considerations | |
| Doubly Linked Lists | O(n) average/worst case | O(1) | O(n) average/worst case | O(1) | O(1) | data structure to beat for this assignment |
| Binary Heaps | O(lg n) average/worst case | O(lg n) average/worst case | O(lg n) average/worst case | O(1) | O(lg n) average/worst case | efficient, simple to implement and debug |
| Binomial Queues | O(lg n) worst case | O(lg n) average/worst case | O(lg n) average/worst case | O(1) | O(lg n) average/worst case | difficult to implement, main advantage is the Union operation [CLRS] |
| Leftist Trees | O(lg n) | O(1) to mark the node only, deleted later | O(lg n) | O(1) | O(lg n) | 30% slower than standard heaps [Jones86] |
| Pagodas | O(n) worst case for some operations, complicated implementation [Mhatre01] | |||||
| Fibonacci Heaps | O(1) amortized | O(lg n) amortized | O(1) amortized | O(1) amortized | O(lg n) amortized | best when Extract-Max and Delete are called infrequently [CLRS], better for large queue sizes |
| Modified Binary Heaps
(My solution) |
O(1) on invalid heap, O(lg n) on valid heap (amortized) | O(lg n) amortized | O(1) amortized | O(1) amortized | O(lg n) amortized | simple but efficient, especially when Extract-Max is followed by Insert |
The textbook [CLRS] and [Mhatre01]
were of tremendous help in filling in this table. While searching
for algorithms, I was looking for a data structure that was relatively
straightforward to implement and debug (since I was working by myself),
but also performed well compared to the other alternatives. After
reviewing all the other data structures, I determined that the simple binary
heaps represented the ideal tradeoff between performance and ease of implementation.
It also provided the benefit of only requiring the memory to be allocated
once (provided we know the maximum heap size), and once it was created
all of the operations could be performed in place. Once I noticed
I could even improve the performance of binary heaps for the purpose of
the scheduler using the modifications I have presented here, I felt I had
been able to create a solution that was on par with the best from the list
above!
The development of the algorithm presented here was not developed all at once. It took a series of improvements. First I implemented a binary heap exactly as it appeared in CLRS (Rev. 1). Then I noticed that I could modify the algorithm to defer fixing the heap until the call following Extract-Max, since so often it was following by an Insert (Rev. 2). Finally, I noticed that it was unnecessary to copy the node for the client in Extract-Max, since it was only needed temporarily by the scheduler (Rev. 3). In Rev. 3, I also optimized the code itself as much as possible, using pointer arithmetic instead of array accesses and other such speed-ups I have learned over the years. In the end, I was able to develop an implementation that equaled or outperformed the supplied doubly linked list in every case, including the test file "test.10000.a", which was supposedly one of the best case performances of that implementation. While my implementation required slightly more comparisons for that input file, the fact that no memory needed to be allocated in my implementation probably made up the difference. The following table shows the evolution of my project (all tests were performed on elaine27 and averaged over 5 trials). Rev. 3 is what I have submitted with this report, and clearly shows a significant improvement from both the doubly linked list, and just the basic binary heap as defined in CLRS.
Real-Time Performance Improvements of the Binary Heap Implementation
(Total Time (seconds) / Client Time (seconds) / Comparisons)
|
|
(Sample Implemenation) |
(Rev. 1) |
(Rev. 2) |
(Rev. 3) |
| test.100.a |
|
|
|
|
| test.100.b |
|
|
|
|
| test.500.a |
|
|
|
|
| test.500.a.rev |
|
|
|
|
| test.1000.a |
|
|
|
|
| test.10000.a |
|
|
|
|
[CLRS] Cormen, T.H, Leiserson, C.E., Rivest, R.L., and Stein, C.
Introduction to Algorithms, Second Edition. McGraw Hill, 2001.
[Jones86] Jones, D.W., An Empirical Comparison of Priority-Queue and
Event-Set-Implementations. Communications of the ACM, 1986. 29(4): p. 300-311.
[Mhatre01] Mhatre, N., A Comparative Performance Analysis of Real-Time
Priority Queues. Master's Thesis, Fall 2001, Florida State University.